RabbitMQ基础
RabbitMQ
RabbitMQ介绍
RabbitMQ 是采用 Erlang 语言实现 AMQP(Advanced Message Queuing Protocol,高级消息队列协议)的消息中间件,它最初起源于金融系统,用于在分布式系统中存储转发消息。
RabbitMQ 的具体特点可以概括为以下几点:
- 可靠性: 通过自身机制保证其可靠性,如持久化、传输确认及发布确认等
- 灵活的路由:
- 扩展性: 多个RabbitMQ节点可以组成一个集群
- 高可用性
- 支持多种协议
- 多语言客户端
- 易用的管理界面: 官方提供ui工具
- 插件机制
RabbitMQ核心概念
RabbitMQ 整体上是一个生产者与消费者模型,主要负责接收、存储和转发消息。机构模型如下图:
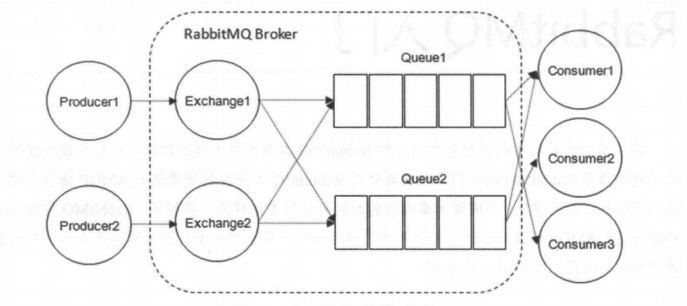
生产者(Producer) 和 消费者(Consumer)
- 生产者: 消息投放者
- 消费者: 消息消费者
消息一般由两部分组成: 消息头和消息体。消息体不透明。RabbitMQ根据消息头进行转发
Exchange(交换器)
RoutingKey: 生产者将消息交给交换器时,一般会指定一个RoutingKey(路由键),用来指定这个路由规则,而这个路由键需要与绑定键联合使用才能最终生效。
BindingKey: 确定了不同的交换器(Exchange),那么我们还需要将交换器和消息队列进行关联。我们可以通过BindingKey(绑定键)进行关联。其中绑定关系是多对多的。多个队列可以使用相同的绑定键(Binding Key)。
交换器是用来接收生产者发送的消息,并将这些消息路由给对应的服务器队列,如果路由失败,或许会返回给生产者,或者直接丢弃。也就是说,生产者的消息并不会直接交给Queue(消息队列),而且需要先通过Exchange(交换器)进行路由。
Exchange分为四个类型,不同的类型,路由规则也不同:
- direct: 把消息路由到绑定键(BindingKey)和路由键(RoutingKey)完全匹配的队列中
- fanout: 把所有的发送到Exchange中的消息路由到它绑定的Queue,不需要其它操作,速度最快。可以用来做广播
- topic: topic类型的交换器在匹配规则上进行了扩展,它与 direct 类型的交换器相似,也是将消息路由到
BindingKey和RoutingKey相匹配的队列中,但这里的匹配规则有些不同,它约定:- RoutingKey 为一个点号“.”分隔的字符串(被点号“.”分隔开的每一段独立的字符串称为一个单词),如 “com.rabbitmq.client”、“java.util.concurrent”、“com.hidden.client”
- BindingKey 和 RoutingKey 一样也是点号“.”分隔的字符串
- BindingKey 中可以存在两种特殊字符串“”和“#”,用于做模糊匹配,其中“”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)
- headers: 不推荐。根据发送的消息内容中的 headers 属性进行匹配。
消息队列(Queue)
Queue(消息队列) 用来保存消息直到发送给消费者。它是消息的容器,也是消息的终点。一个消息可投入一个或多个队列。消息一直在队列里面,等待消费者连接到这个队列将其取走。
多个消费者可以订阅同一个队列,这时队列中的消息会被平均分摊(Round-Robin,即轮询)给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理,这样避免消息被重复消费。RabbitMQ不支持队列层面的广播消费。
服务节点(Broker)
对于RabbitMQ来说,一个RabbitMQ Broker可以简单地看作一个RabbitMQ服务节点,或者RabbitMQ服务实例。大多数情况下也可以将一个 RabbitMQ Broker 看作一台RabbitMQ服务器
死信队列
DLX,全称为Dead-Letter-Exchange,死信交换器,死信邮箱。当消息在一个队列中变成死信 (dead message) 之后,它能被重新被发送到另一个交换器中,这个交换器就是DLX,绑定DLX的队列就称之为死信队列
导致死信的原因:
- 消息被拒绝
- 消息ttl过期
- 队列满了,无法再添加
如何保证可靠性
生产者到mq: 事务机制和Confirm机制。这两个是互斥的,不能共存。
mq自身: 持久化,集群,普通模式,镜像模式
mq到消费者: basicAck机制,死信队列,消息补偿机制
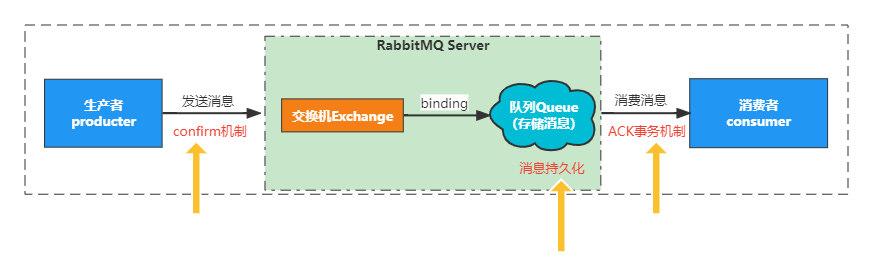
持久化
如果我们需要将消息进行持久化,一般我们可以在创建队列的进行配置,通过参数durable配置实现
1 | // 创建的队列的方法,也和下面的注解方法相同 |
confirms or 事务
因为这两个机制是互斥的,我们只需要使用其中一种就可以
confirms: 生产者将消息发送给服务器,就会通过回调confirms()来通知生产者
returnedMessage: 若交换机不能路由到队列,则回调returnedMessage()来通知生产者
几个注解
@Queue
@QueueBinding使用时用来定义队列信息的注解
1 | public Queue { |
@Exchange
1 | public Exchange { |
@QueueBinding
定义一个queue,一个exchange,和一个可选的绑定键
1 | public QueueBinding { |
@RabbitListener
标记一个方法做为指定的queues()或者binds()的监听器。都会将其配置放入MethodRabbitListenerEndpoint中进行注册
当这边注解用于类上时,一个单独的消息监听容器将会为所有带有@RabbitHandler注解的方法提供服务。各个方法都是不能相同的,这样才能为特定入站消息解析
1 | public RabbitListener { |
除了这个注解的属性,被这个注解标记的方法,还会给该方法提供灵活的行参,类似于注解@MessageMapping
多个消息队列优缺点对比整理
基础点对比
| 组件 | kafka | RocketMQ | RabbitMQ | ActiveMQ |
|---|---|---|---|---|
| 推出时间 | 2012 | 2012 | 2007 | |
| 公司 | linkin开源-apache | 阿里开源-apache | pivotal开源-mozilla | |
| 开发语言 | scala & Java | Java | erlang | |
| 吞吐量 | 十万级 | 万级 | 万级 | 单机万级 |
| 延迟 | 毫秒级 | 毫秒级 | 微秒级 | |
| 主题数 | 几十到几百 | 几百到几千 | Thousands | |
| 高可用 | 高(分布式) | 高(主从) | 高(主从) | 高 |
| 消息丢失 | 理论上不会 | 理论上不会 | 低 | 低 |
| 消息重复 | 理论上有重复 | 可控制 | ||
| 推荐度 | 推荐 | 推荐 | 推荐 | 不推荐(性能差,更新慢) |
优缺点总结
kafka
优点:
- 高吞肚,低延迟
- 高伸缩性
- 高稳定性: 分布式架构,一个数据多个副本
- 持久性,可靠性,可回溯性
- 消息有序: 一个消息被消费且仅有一次
- ui管理节目优秀
- 兼容性好
缺点:
- 不支持消息路由,不支持延迟发送,不支持消息重试;
- 社区更新慢
- 单机分区/队列超过64,load飙高,消息响应需要时间变长
场景选择: 大量数据的互联网服务的数据收集业务
RocketMQ
优点:
- 高吞吐: 单一队列百万消息的堆积能力
- 高伸缩性: 灵活部署
- 高容错性: ack机制,保证消息一定能消费
- 持久化、可回溯: 持久化在磁盘中
- 消息有序: fifo原则和严格的顺序传递
- 提供docker镜像集群部署和功能丰富的dashboard
缺点:
- 不支持消息路由,支持的客户端语言不多,主要为Java
- 社区活跃度一般
场景选择: 面向要求可靠性很高的场景,比如金融互联网领域。并且可以参考阿里成熟的实战场景和案例,也可以进行二次开发,定制自己的mq
RabbitMQ
优点:
- 支持所有受欢迎的语言
- 支持消息路由: 通过不同交换器支持不同的消息路由
- 消息时序: 可以有延时队列,指定消息的延时时间,过期时间ttl等
- 支持容错: 交付重试已经死信队列
- ui管理节目
- 社区活跃
缺点:
- erlang开发,不利于二次开发
- 吞吐量略低
- 不支持消息有序、持久化不好、不支持消息回溯、伸缩性一般
场景选型: 并发能力强,性能较好,社区活跃,如果吞吐量不是特别大,没有二次开发需求,可以选择使用
